Datensätze
Nach Datensatz suchen¶
Bevor Sie einen neuen Datensatz erstellen sollten Sie zunächst prüfen, ob dieser Datensatz bereits vorhanden ist. Sie können im Katalog nach vorhandenen Datensätzen suchen, indem Sie mindestens drei Zeichen in das Suchfeld eingeben.
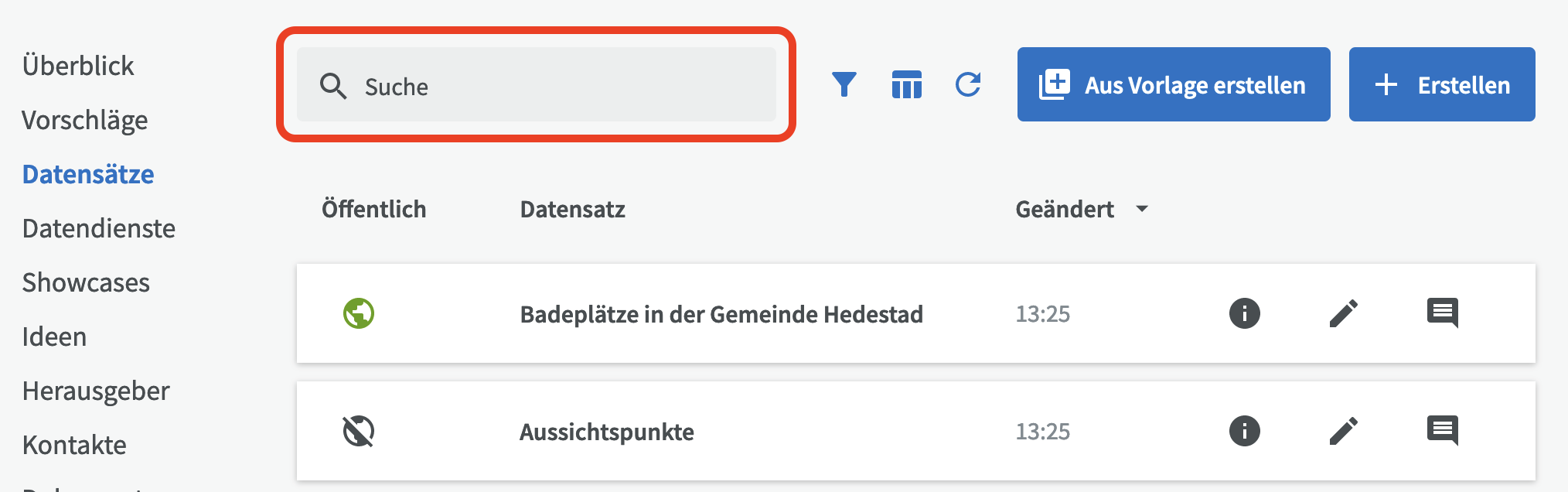
Wenn der Datensatz noch nicht existiert können Sie einen neuen Datensatz erstellen.
Suchfilter¶
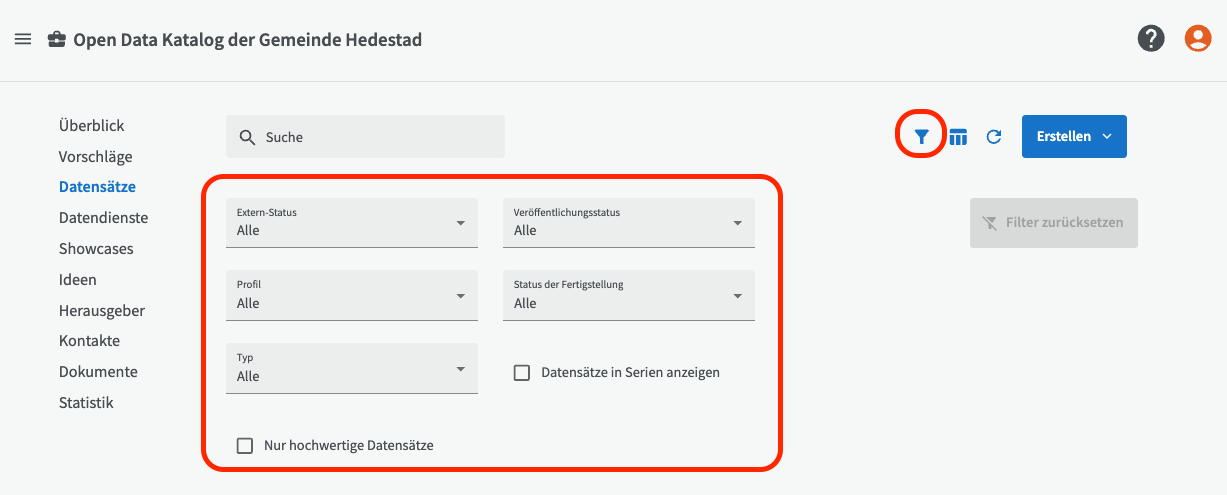
Sie können auch die Filterfunktion verwenden, um beispielsweise nach intern oder extern veröffentlichten Datensätzen, sowie nach veröffentlichten oder unveröffentlichten Datensätzen zu filtern. Aktivieren Sie den Filter, indem Sie oben rechts auf das Filter-Symbol klicken.
Datensatz aus Vorlage erstellen¶
Es gibt zwei verschiedene Möglichkeiten einen Datensatz zu erstellen: entweder Sie erstellen ihn anhand einer Vorlage die bereits vorhanden ist, oder Sie erstellen ihn von Grund auf neu.
Um einen Datensatz aus einer Vorlage zu erstellen, klicken Sie auf die Schaltfläche "Erstellen", wählen anschließend "Datensatz aus Vorlage" und suchen sich einen geeigneten Katalog und ggf. eine passende Kategorie (zum Beispiel „Umwelt“) aus, in der sich eine brauchbare Vorlage für den zu erstellenden Datensatz befinden könnte.
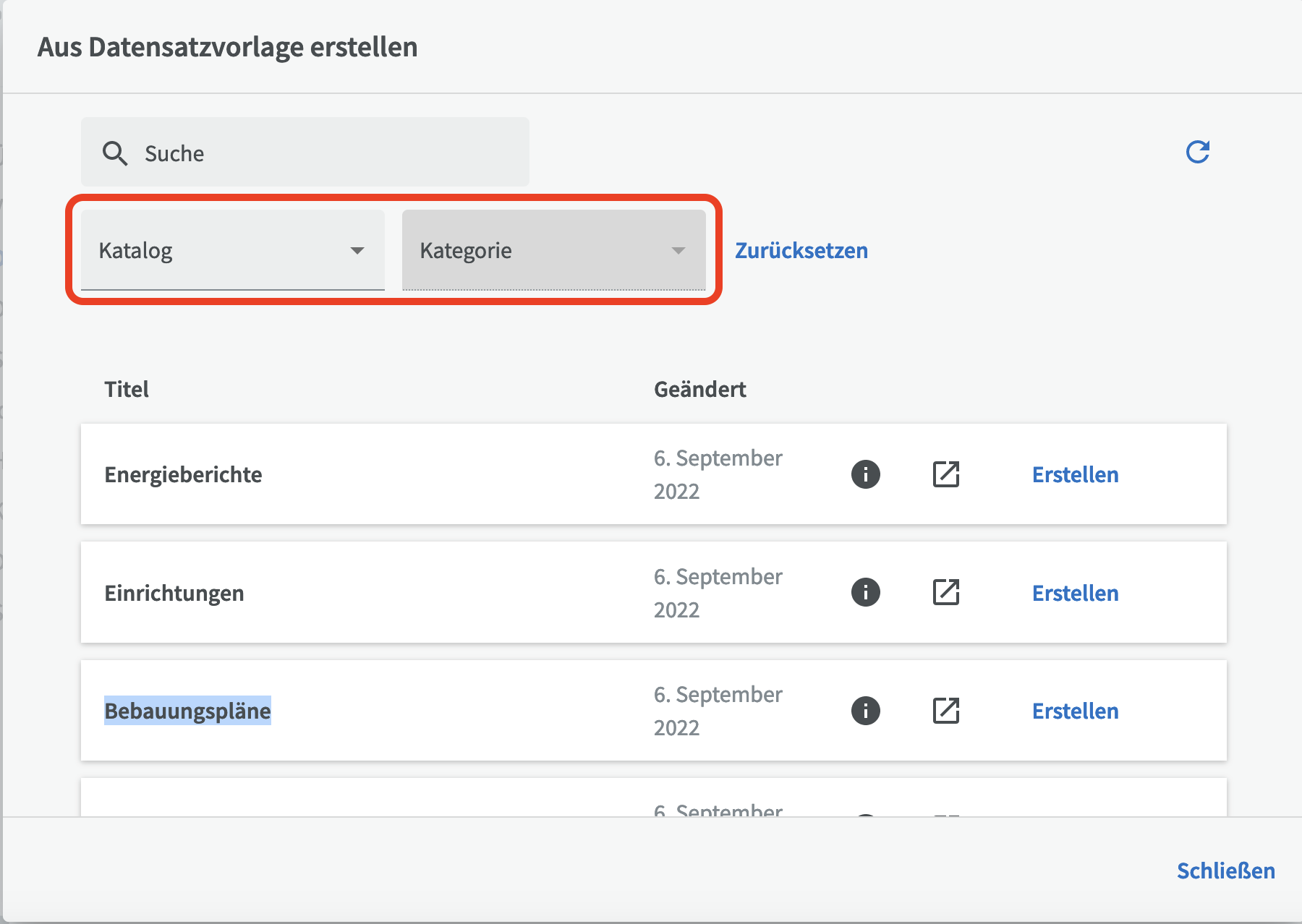
Um eine Vorschau der Datensatzbeschreibung zu erhalten, klicken Sie auf das runde Informationssymbol. Wenn Sie die ausgewählte Vorlage verwenden möchten, klicken Sie auf "Erstellen".
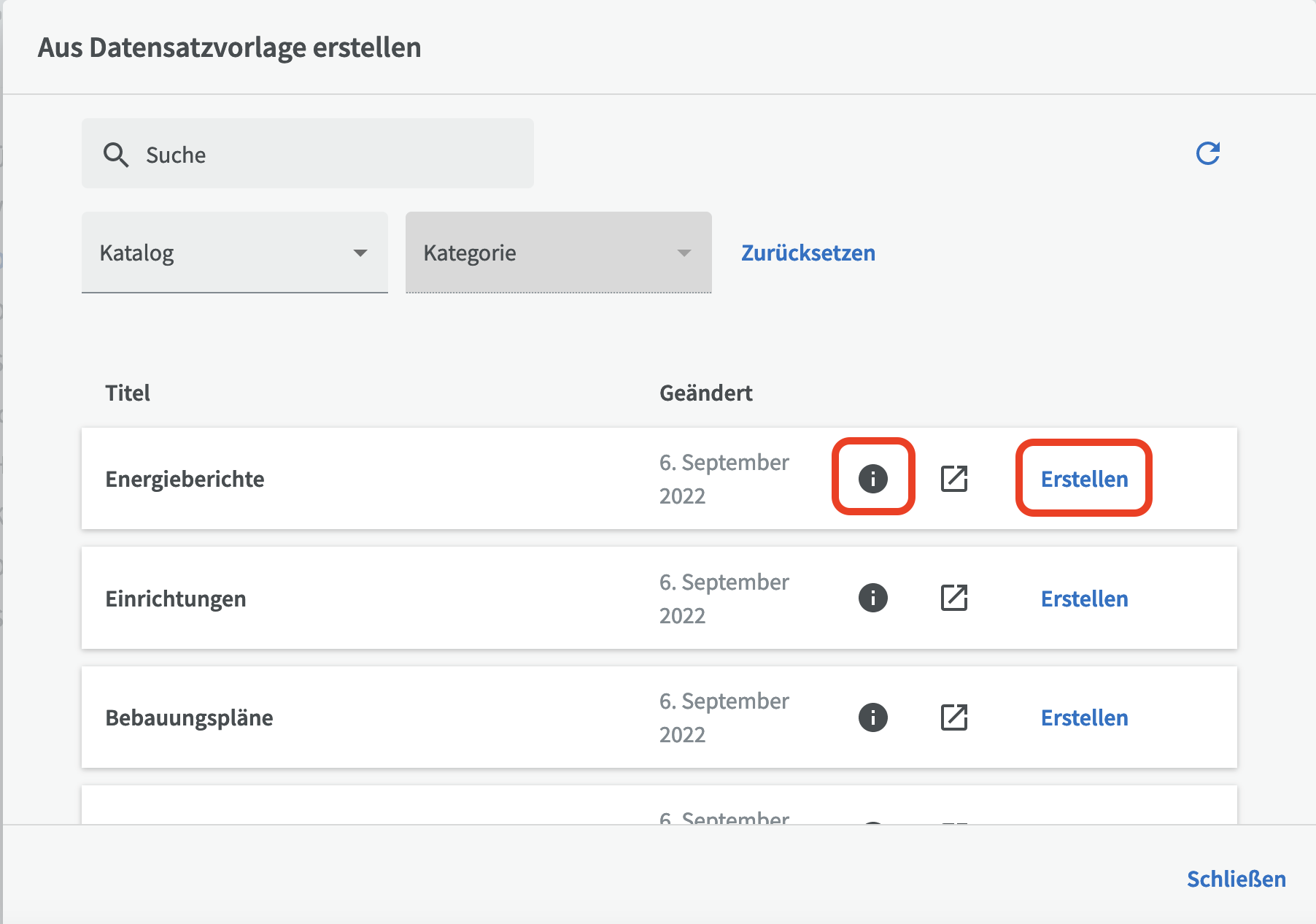
Sie erhalten eine Seite mit vorab eingegebenen Informationen aus der Vorlage, die Sie bearbeiten können, um sie an Ihren Datensatz anzupassen.
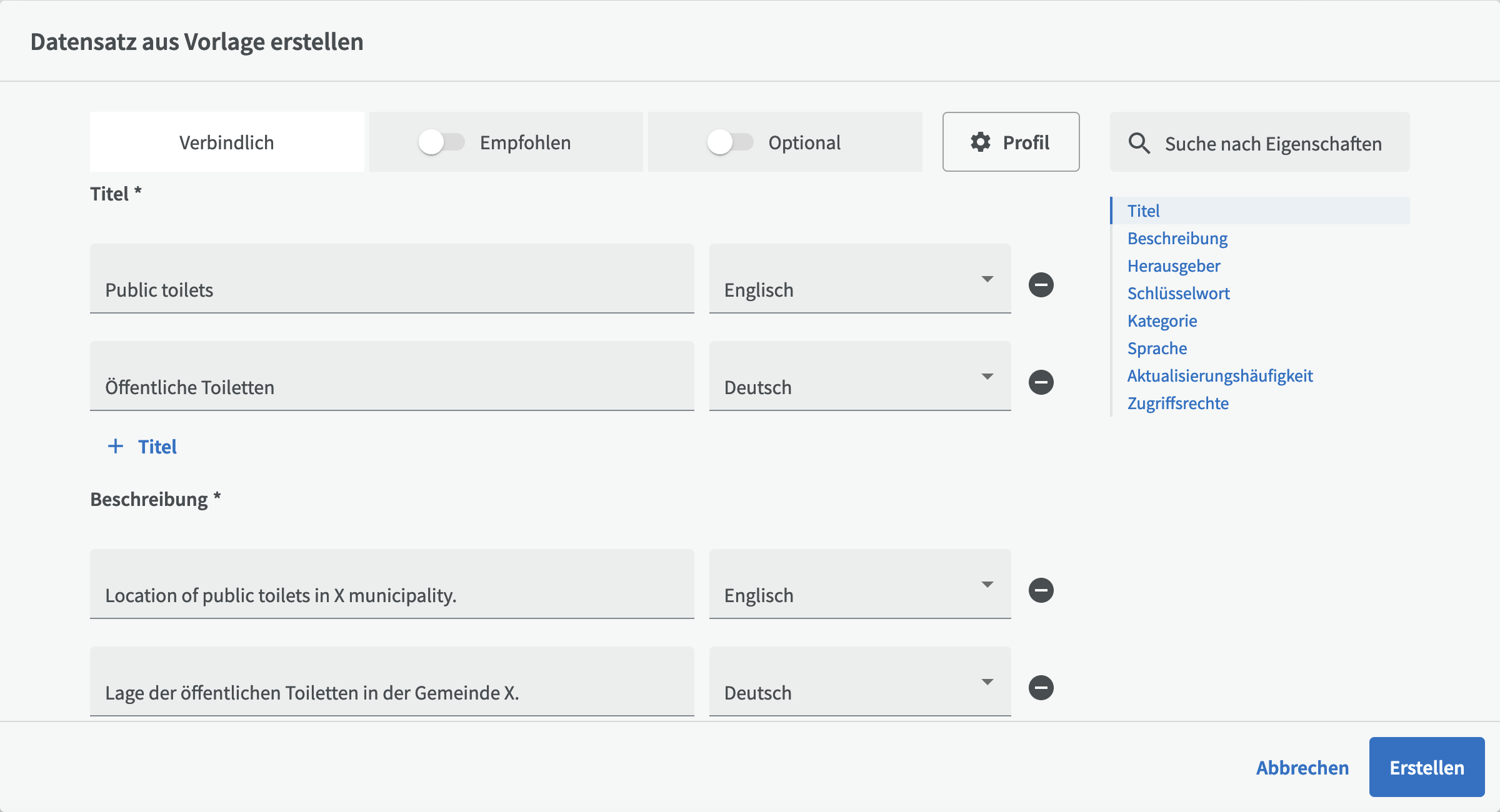
Durch Aktivieren der empfohlenen und optionalen Felder können Sie Ihren Datensatz detaillierter beschreiben. Weitere Informationen zu den einzelnen Eingabefeldern finden Sie unter Beschreibung eines Datensatzes.
Sie können nur einen Datensatz aus einer Vorlage erstellen. Wenn Sie jedoch mehrere ähnliche Datensätze erstellen möchten, lesen Sie den Abschnitt Datensatz kopieren.
Einen Datensatz von Grund auf neu erstellen¶
Wenn Sie einen Datensatz von Grund auf neu erstellen möchten, anstatt eine Vorlage zu verwenden, klicken Sie auf die Schaltfläche "Erstellen" und wählen Sie dann "Datensatz".
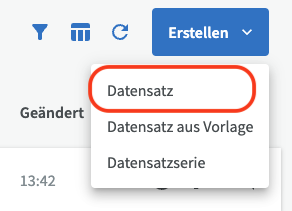
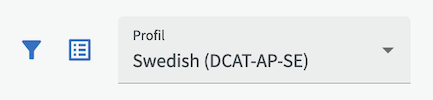
Wählen Sie zunächst ein Profil aus das zu Ihrem Datensatz passt bevor Sie Informationen in die Eingabefelder eingeben. Wenn Sie keine Profilschaltfläche sehen ist das Profil bereits für Sie ausgewählt. Das von Ihnen ausgewählte Profil bestimmt, welche Eingabefelder Ihr Datensatz enthält. Das am häufigsten verwendete Profil ist in der Regel der voreingestellte Standard.

Die Organisation kann Daten gemäß verschiedener Anwendungsprofile veröffentlichen. Für PSI-Daten kann dies DCAT-AP und für INSPIRE eine Kombination aus GeoDCAT-AP und DCAT-AP sein. Wenn Sie mit Geodaten arbeiten, sollten Sie das INSPIRE-Profil verwenden.
Einen Datensatz beschreiben¶
Wenn Sie ein geeignetes Profil ausgewählt haben, können Sie mit der Beschreibung Ihres Datensatzes beginnen. Alle obligatorischen und empfohlenen Eingabefelder werden standardmäßig angezeigt. Sie können die empfohlenen und optionalen Eingabefelder auf der Bearbeitungsseite mithilfe der Schieberegler oben anzeigen oder ausblenden. Eingabefelder die bereits Daten enthalten werden immer angezeigt.
Auf der rechten Seite sehen Sie Schnellzugriffs-Links zu allen Eingabefeldern. Wenn Sie auf den Titel eines Eingabefeldes klicken, erhalten Sie eine Felderklärung mit einer kurzen Beschreibung der erwarteten Eingabe und in einigen Fällen Links zu DCAT-AP oder entsprechenden Beschreibungen.
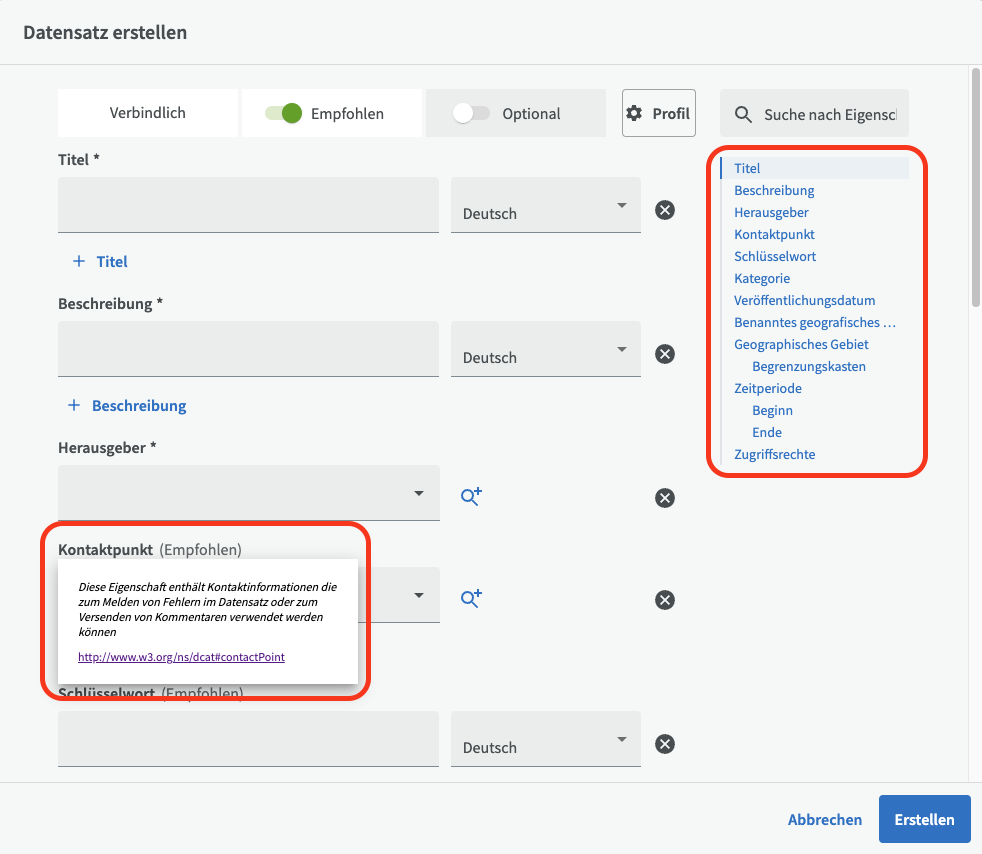
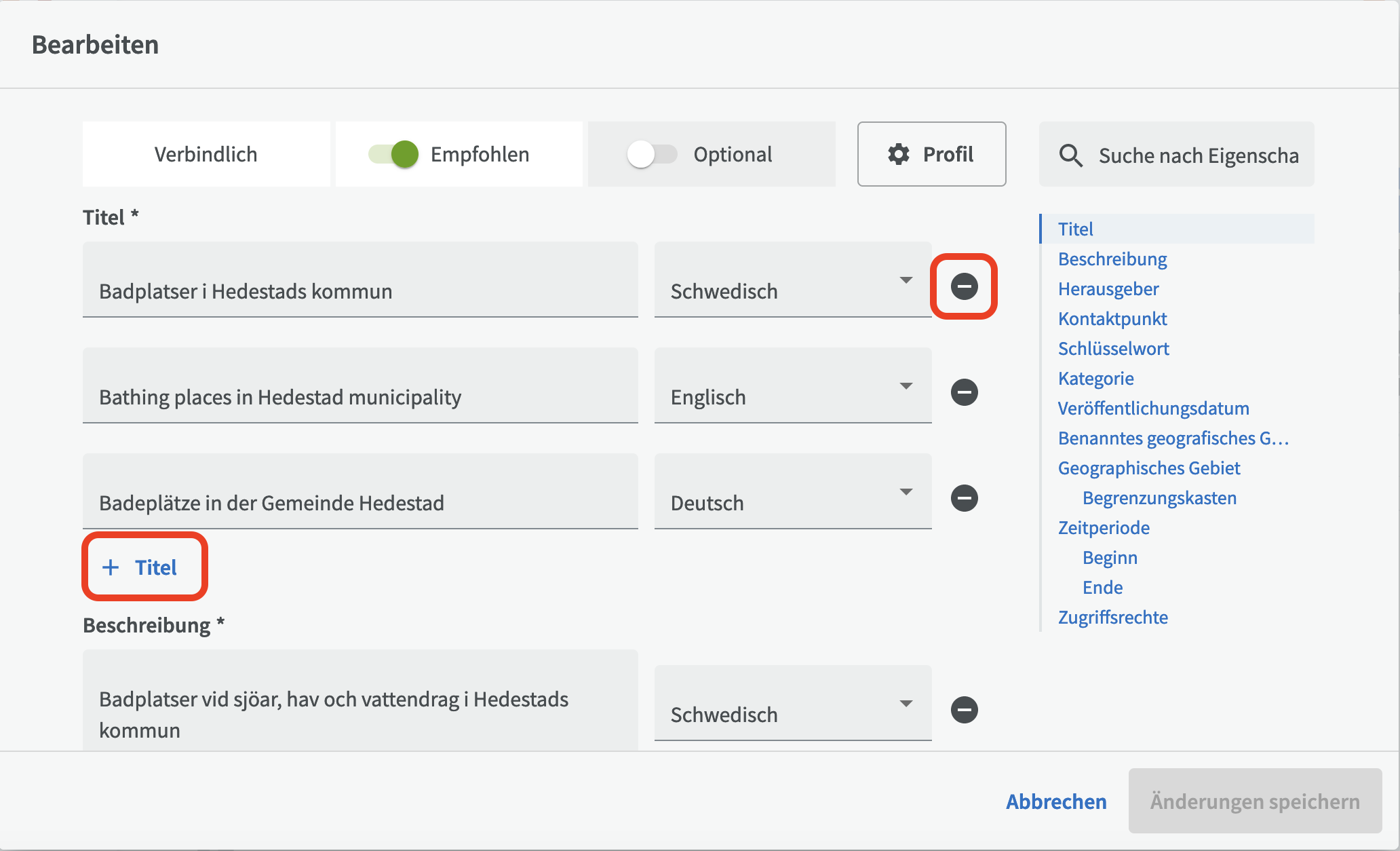
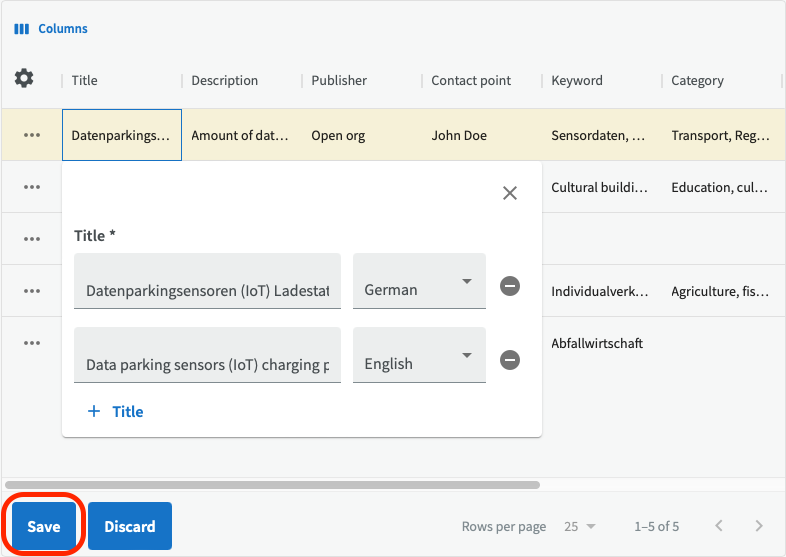
Die drei Felder "Titel", "Beschreibung" und "Herausgeber" sind Pflichtfelder für einen Datensatz. Denken Sie daran, dass Ihre Organisation möglicherweise verlangt, dass Sie Informationen in Pflichtfeldern in mehr als einer Sprache eingeben. Um einen Titel in einer anderen Sprache hinzuzufügen, klicken Sie auf "+ Titel". Es wird eine neue Zeile mit Eingabefeldern angezeigt, in der Sie andere Sprachen auswählen können. Wenn Sie stattdessen eine Zeile entfernen möchten, klicken Sie auf das Minuszeichen auf der rechten Seite.
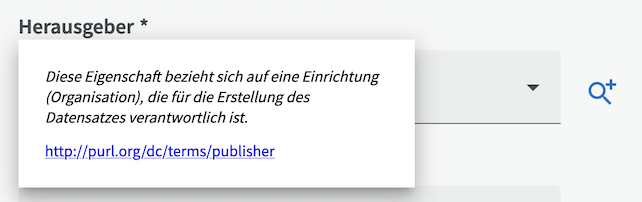
Hinweis! Wenn ein externer Teil den Datensatz für eine Organisation bereitstellt, sollte diese Organisation als Herausgeber für den Datensatz eingetragen werden. Der Grund dafür ist, dass die ursprüngliche Organisation nur Regeln dafür festlegen kann, wie der externe Bereitsteller mit den Daten umgehen soll, aber in Wirklichkeit keine Kontrolle über die Daten ausüben kann.
Entwürfe¶
Sie können die Metadaten des Datensatzes speichern, auch wenn Sie nicht alle erforderlichen Felder ausgefüllt haben. Der Datensatz wird dann zu einem Entwurf und kann ganz einfach mit anderen Benutzern geteilt werden, auch wenn er noch nicht fertig ist.
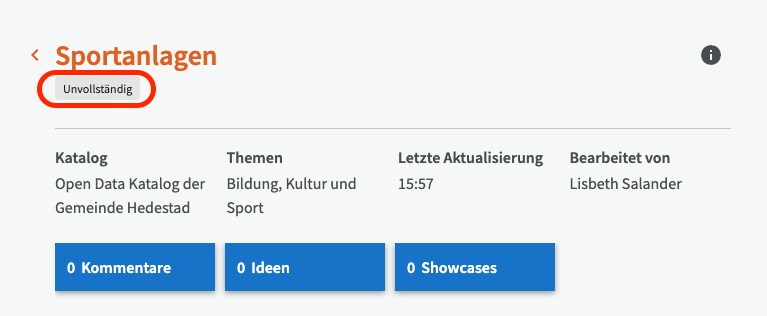
Der Entwurf wird in der Liste der Datensätze mit einem roten Warnsymbol angezeigt, das darauf hinweist, dass es sich um einen unvollständigen Datensatz handelt, der erst veröffentlicht werden kann, wenn alle erforderlichen Felder ausgefüllt sind.
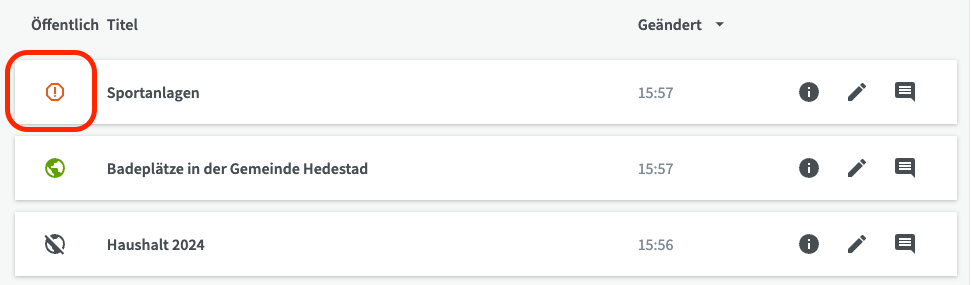
Auf der Übersichtsseite des Datensatzes wird er mit dem Tag "unvollständig" angezeigt. Wenn die Pflichtfelder später ausgefüllt werden, verschwinden das rote Warnsymbol und das Tag "unvollständig" automatisch.
Für weitere Informationen zu den empfohlenen und optionalen Feldern wenden Sie sich an die Spezifikation der von Ihnen verwendeten DCAT-AP-Variante.
Entspricht¶
Das Feld "Entspricht" wird verwendet, um auf eine Spezifikation oder Anwendungsvorschrift zu verweisen, die für den Datensatz gilt. (Wenn der Datensatz zu einer Datensatzserie gehört, sollte auch die Datensatzserie über das Feld "Entspricht" auf dieselbe Spezifikation wie die darin enthaltenen Datensätze verweisen.) Je nachdem, ob Sie DCAT 3 oder DCAT 2 verwenden, finden Sie das Feld "Entspricht" unter den empfohlenen Feldern bzw. den optionalen Feldern.
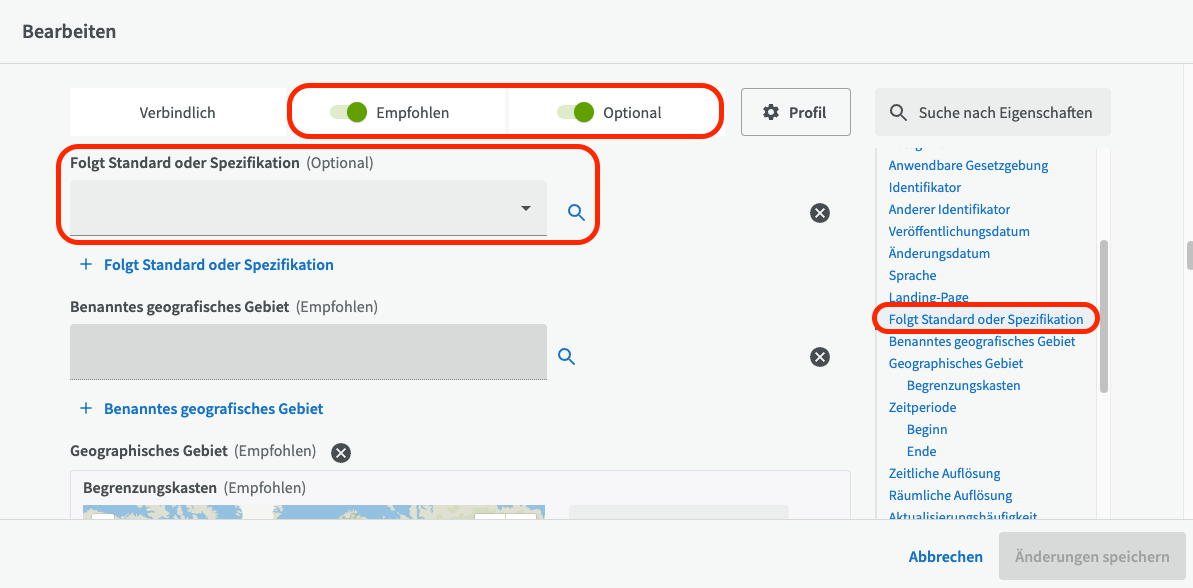
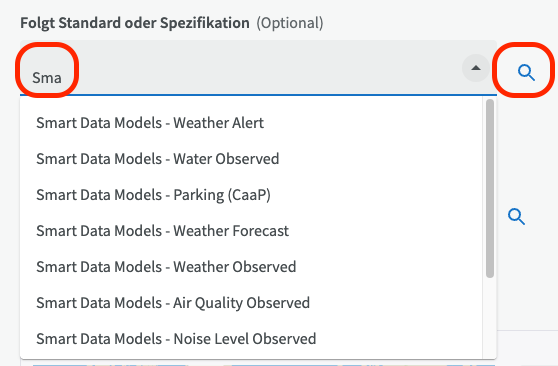
Sie können auf eine Spezifikation verweisen, die Sie über die Funktion Dokumente in EntryScape hochgeladen oder verlinkt haben.
Sie können eine Spezifikation über das Suchfeld suchen oder auf das Lupensymbol klicken, um durch die Spezifikationen zu blättern. Beachten Sie, dass das Dokument vom Dokumenttyp "Standard/Empfehlung/Spezifikation" in Catalog sein muss, um hier sichtbar zu sein.
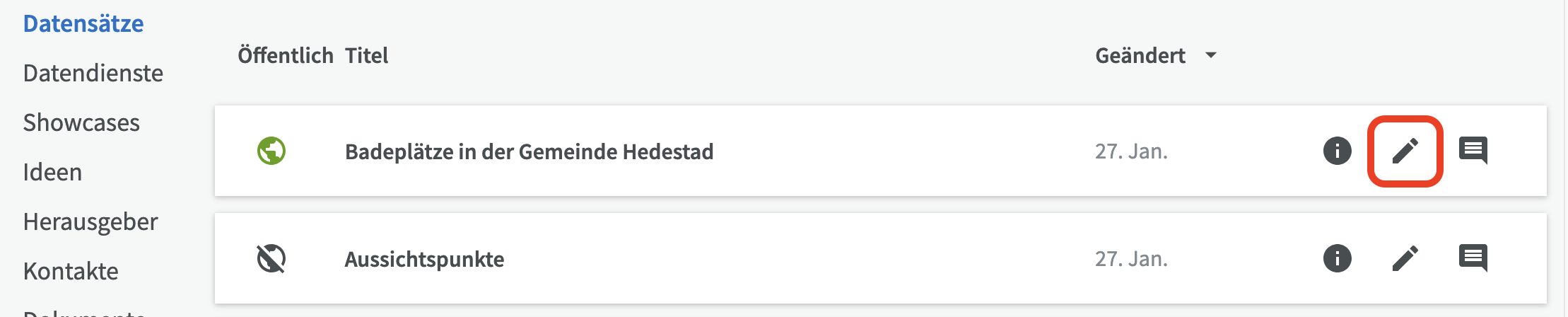
Datensatz bearbeiten¶
Sie können einen Datensatz entweder bearbeiten, indem Sie in der Liste der Datensätze auf den Bleistift klicken, oder Sie können zur Übersichtsseite des Datensatzes gehen und auf die Schaltfläche "Bearbeiten" klicken.

Datensatz aus Datendienst erstellen¶
Ab Version 3.17 von EntryScape können Sie Datensätze basierend auf Datendiensten erstellen, zunächst WMS-Dienste (für Karten).
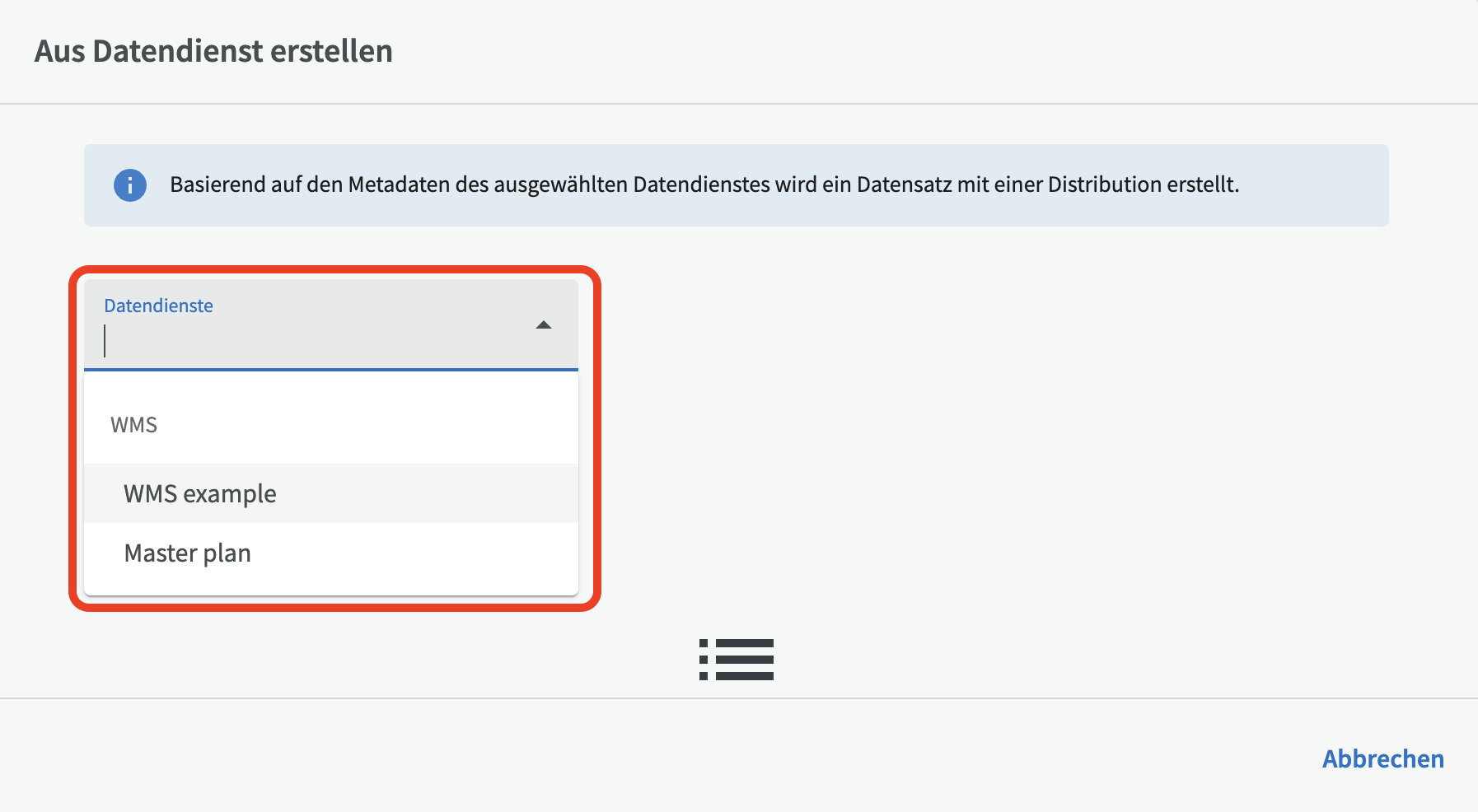
Wählen Sie zunächst den Datendienst aus, den Sie verwenden möchten. Bitte beachten Sie, dass der Datendienst bereits in EntryScape eingegeben worden sein muss, um ausgewählt werden zu können. Wenn Sie hier keine Datendienste sehen, müssen Sie zuerst den Datendienst hinzufügen.
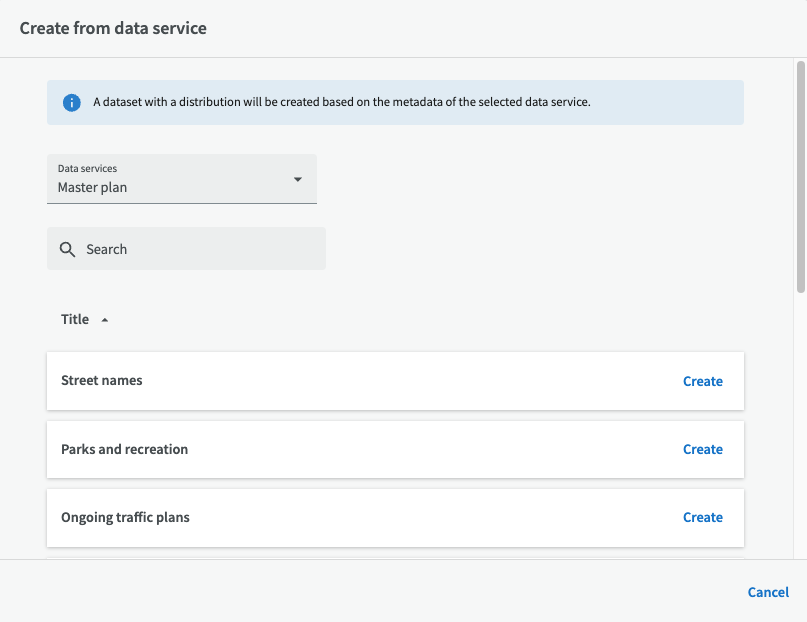
Sobald Sie einen vorhandenen Datendienst (WMS) ausgewählt haben, können Sie wählen, auf welcher Schicht der Datensatz basieren soll. Klicken Sie dann auf "Erstellen".
Füllen Sie dann die Metadaten über den Datensatz aus, wie Titel, Beschreibung, Herausgeber usw.
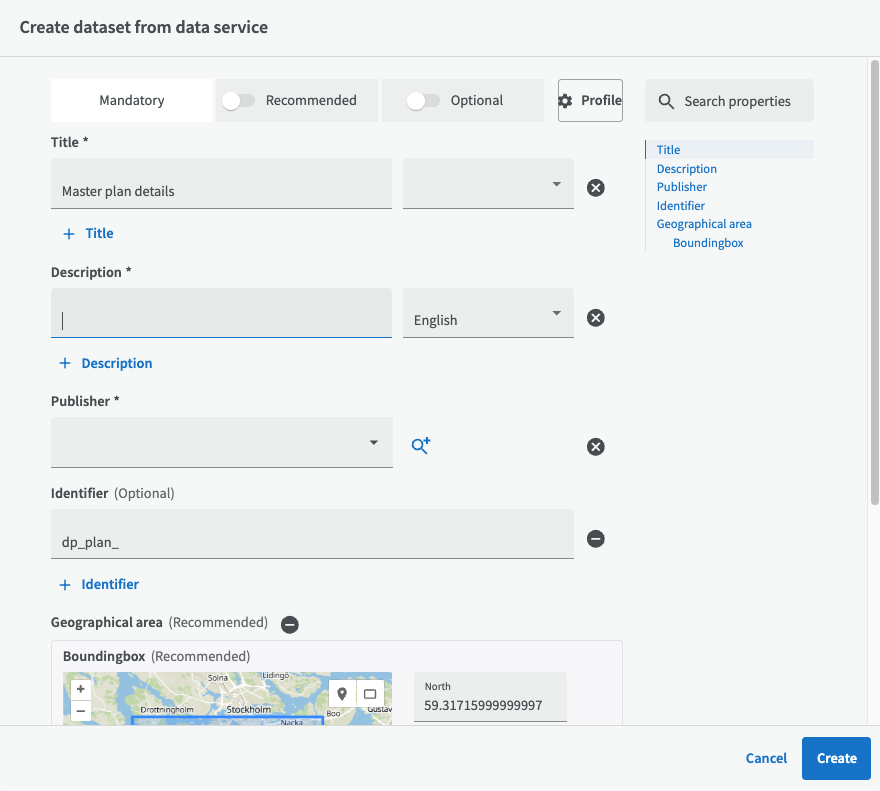
Schließlich wurde ein Datensatz basierend auf einer Schicht eines WMS-Dienstes erstellt. Gleichzeitig wurde auch eine Distribution erstellt, und es ist auch möglich, eine Visualisierung des Datensatzes zu erstellen.
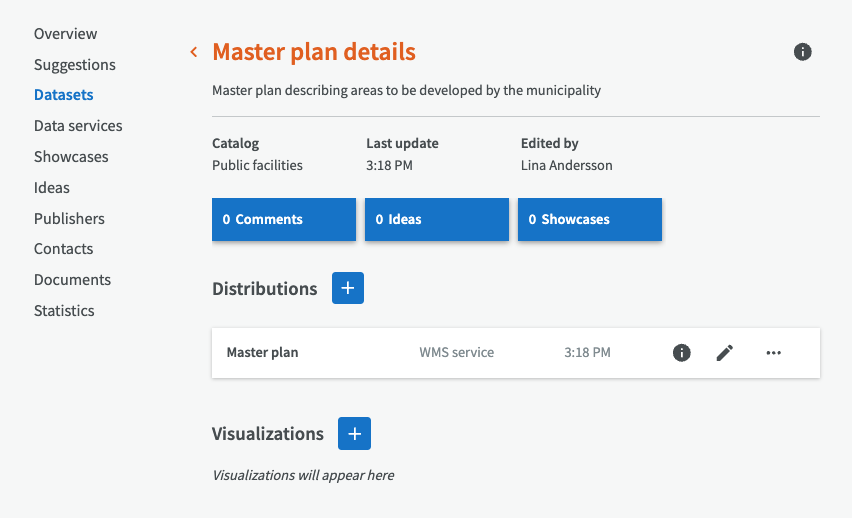
Datensatz sperren¶
Die Sperrfunktion ermöglicht es Gruppenverwaltern, Datensätze für die Bearbeitung zu sperren. Dies ist besonders nützlich, wenn es große Datenmengen gibt, die in Zukunft nicht geändert werden sollen.
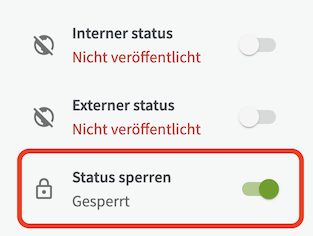
Gesperrte Datensätze werden durch ein kleines Schlosssymbol in der Datensatzliste angezeigt.
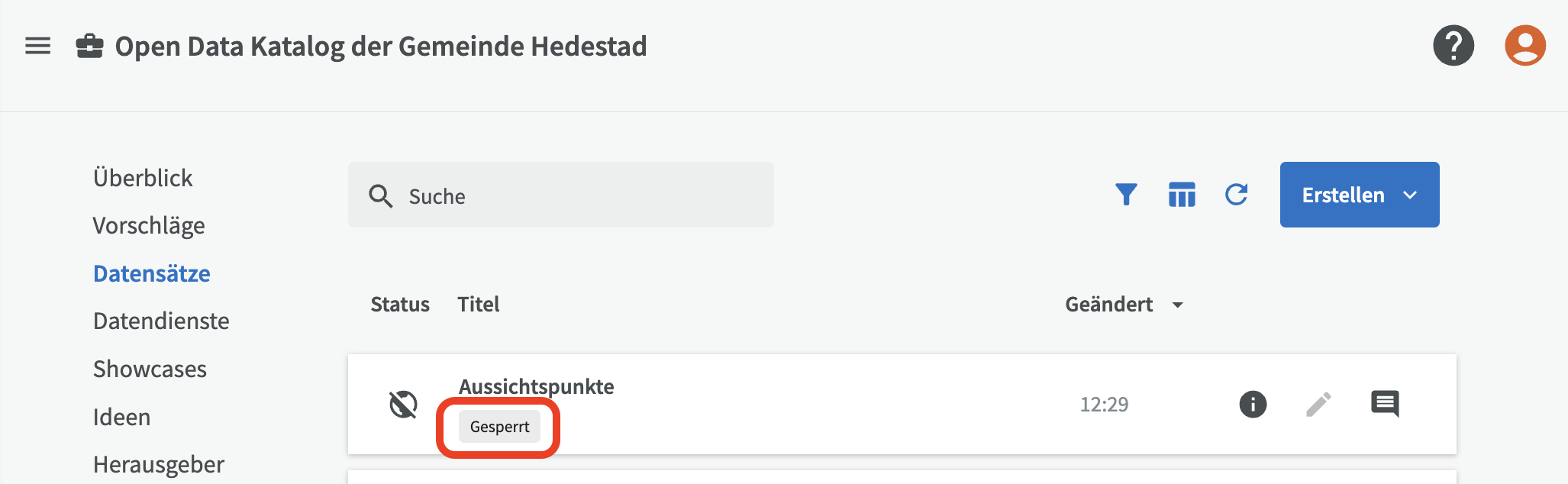
Datensatzserien¶
DCAT-AP 3.0 führt Datensatzserien ein, die auch in EntryScape 3.14 implementiert sind. Datensatzserien können verwendet werden, um zusammengehörende Datensätze zu gruppieren, beispielsweise in Zeitreihen. Wenn Sie in Ihrer Organisation jedoch noch DCAT-AP 2.x verwenden, werden Datensatzserien in Ihrer EntryScape-Instanz deaktiviert, bis Sie auf DCAT-AP 3.0 oder höher aktualisieren.
Es gibt zwei verschiedene Möglichkeiten, eine Datensatzserie zu erstellen:
-
Eine Datensatzserie aus einem vorhandenen Datensatz erstellen. Der Vorteil dabei ist, dass die Datensatzserie dann automatisch Werte direkt aus dem Datensatz übernimmt, sodass Sie nicht viele Felder ausfüllen müssen, die laut Empfehlungen dieselben Daten wie die Datensätze enthalten sollten.
-
Eine Datensatzserie von Grund auf erstellen, ohne vorab ausgefüllte Werte.
1. Datensatzserie basierend auf einem Datensatz erstellen¶
Bei dieser zeitsparenden Methode werden einige der Werte des Datensatzes übernommen, wenn Sie die Datensatzserie erstellen, z.B. Herausgeber, Schlüsselwörter, Kategorie, anwendbare Gesetzgebung, Kategorie für wertvolle Datensätze, Kategorie für Grunddaten, Entspricht, Einstiegsseite, verwandte Ressource, qualifizierte verwandte Ressource sowie Dokumentation.
Um eine Datensatzserie basierend auf einem vorhandenen Datensatz zu erstellen, gehen Sie zu Datensätze, wählen Sie den Datensatz aus, von dem Sie ausgehen möchten, und klicken Sie auf die Schaltfläche "Serien verwalten".

Klicken Sie dann auf die Schaltfläche "Datensatzserie erstellen".

Viele der Felder sind bereits ausgefüllt (kopiert) vom Datensatz, können aber natürlich geändert werden, um besser zur Datensatzserie zu passen.
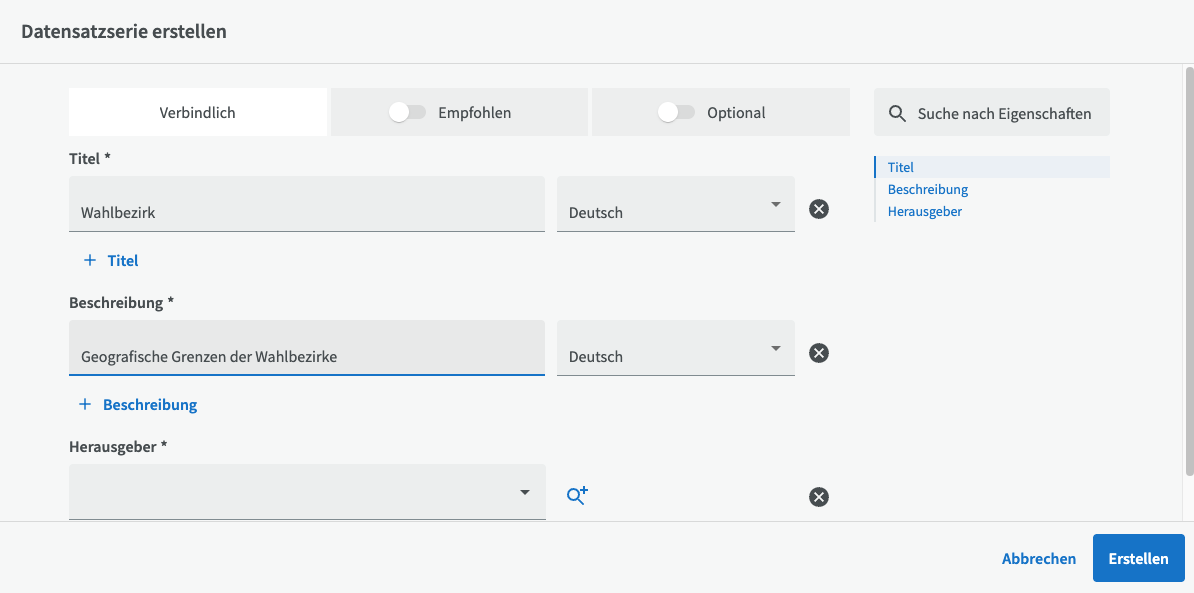
Wichtig ist auch, dass einige der übernommenen Felder möglicherweise nachträglich angepasst werden müssen, wenn die Datensatzserie um weitere Datensätze erweitert wird. Dies gilt insbesondere für die Felder Geografisches Gebiet und Zeitraum.
2. Datensatzserie von Grund auf erstellen¶
Um eine Datensatzserie von Grund auf zu erstellen, gehen Sie zu "Datensätze", klicken Sie auf "Erstellen" und wählen Sie dann "Datensatzserie". Geben Sie einen Titel, eine Beschreibung, einen Herausgeber sowie weitere Informationen ein und klicken Sie auf "Erstellen".
Sie sehen Ihre Datensatzserie in der Liste der Datensätze, markiert mit einem Datensatzserien-Tag.
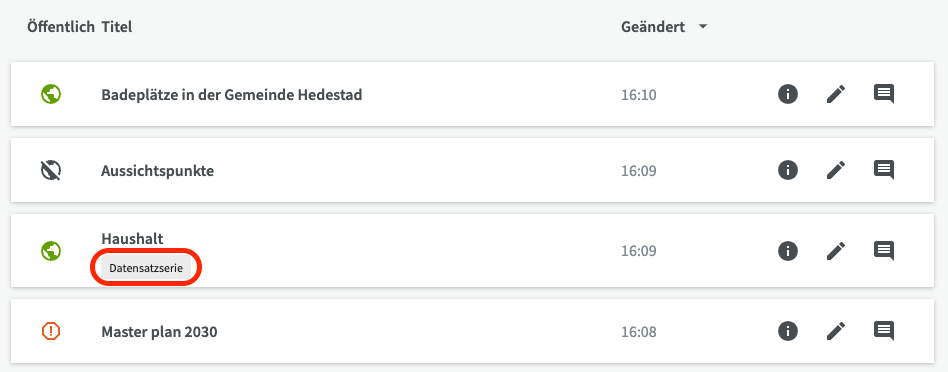
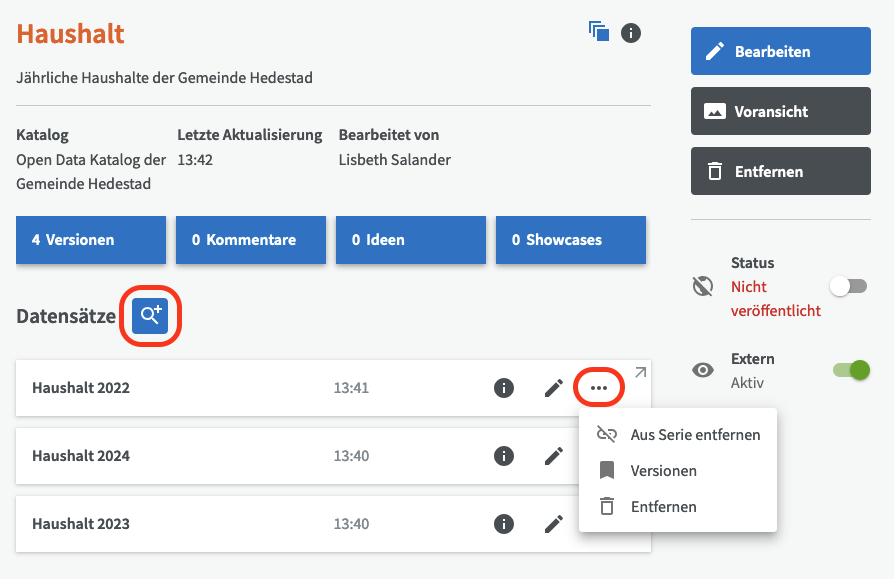
Datensätze zu einer Serie hinzufügen¶
Auf der Übersichtsseite der Datensatzserie können Sie Datensätze hinzufügen, indem Sie auf die Lupe neben "Datensätze" klicken. Wenn Sie einen Datensatz entfernen möchten, können Sie auf das Dreipunktmenü für einen Datensatz klicken und ihn aus der Serie entfernen oder ihn vollständig löschen.
Auf der Übersichtsseite eines Datensatzes können Sie diesen zu einer Datensatzserie hinzufügen oder daraus entfernen, indem Sie auf die Schaltfläche "Serien verwalten" klicken.
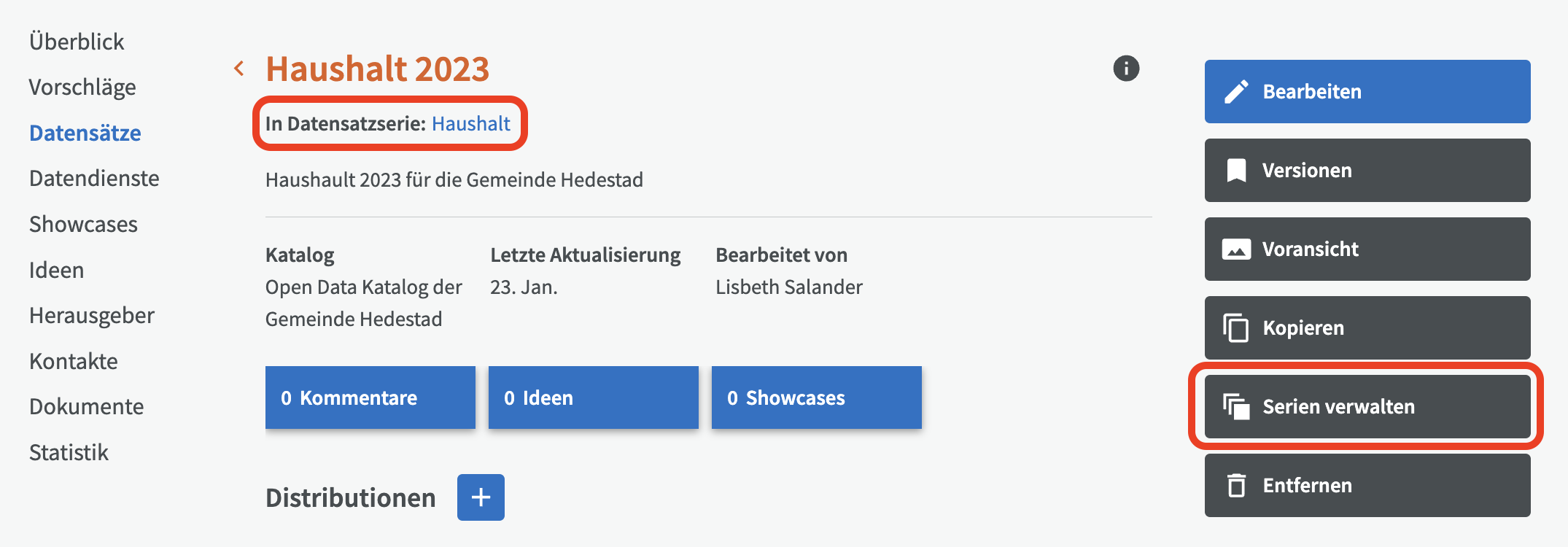
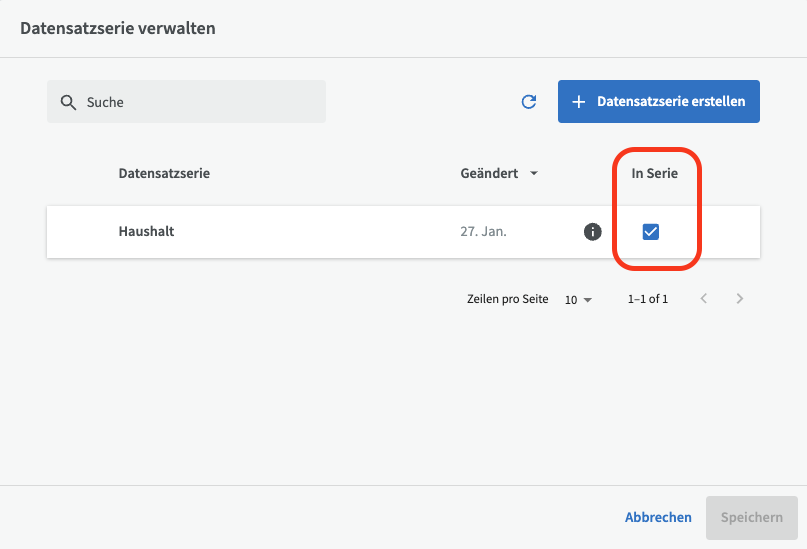
Hinweis! Einzelne Datensätze, die Teil einer Datensatzserie sind, können nicht einzeln veröffentlicht werden. Die gesamte Datensatzserie muss entweder veröffentlicht oder insgesamt zurückgezogen werden. Wenn Sie einzelne Datensätze veröffentlichen und deren Veröffentlichung rückgängig machen möchten, sollten Sie sie nicht in Datensatzserien organisieren.
Generell gilt für Datensatzserien auch, dass das Feld "Entspricht", das beschreibt, welche Spezifikation die Datensatzserie erfüllt, sowohl für die Datensätze als auch für die Datensatzserie ausgefüllt sein sollte. Lesen Sie mehr darüber, wie Sie das Feld Entspricht ausfüllen.
Kontaktstelle erstellen¶
Wenn Sie Ihren Datensatz beschreiben, können Sie auch einen neuen Kontaktpunkt erstellen, indem Sie auf die Lupe klicken.
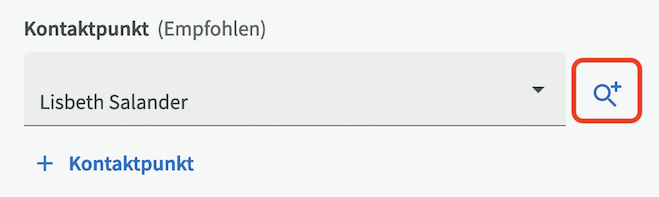
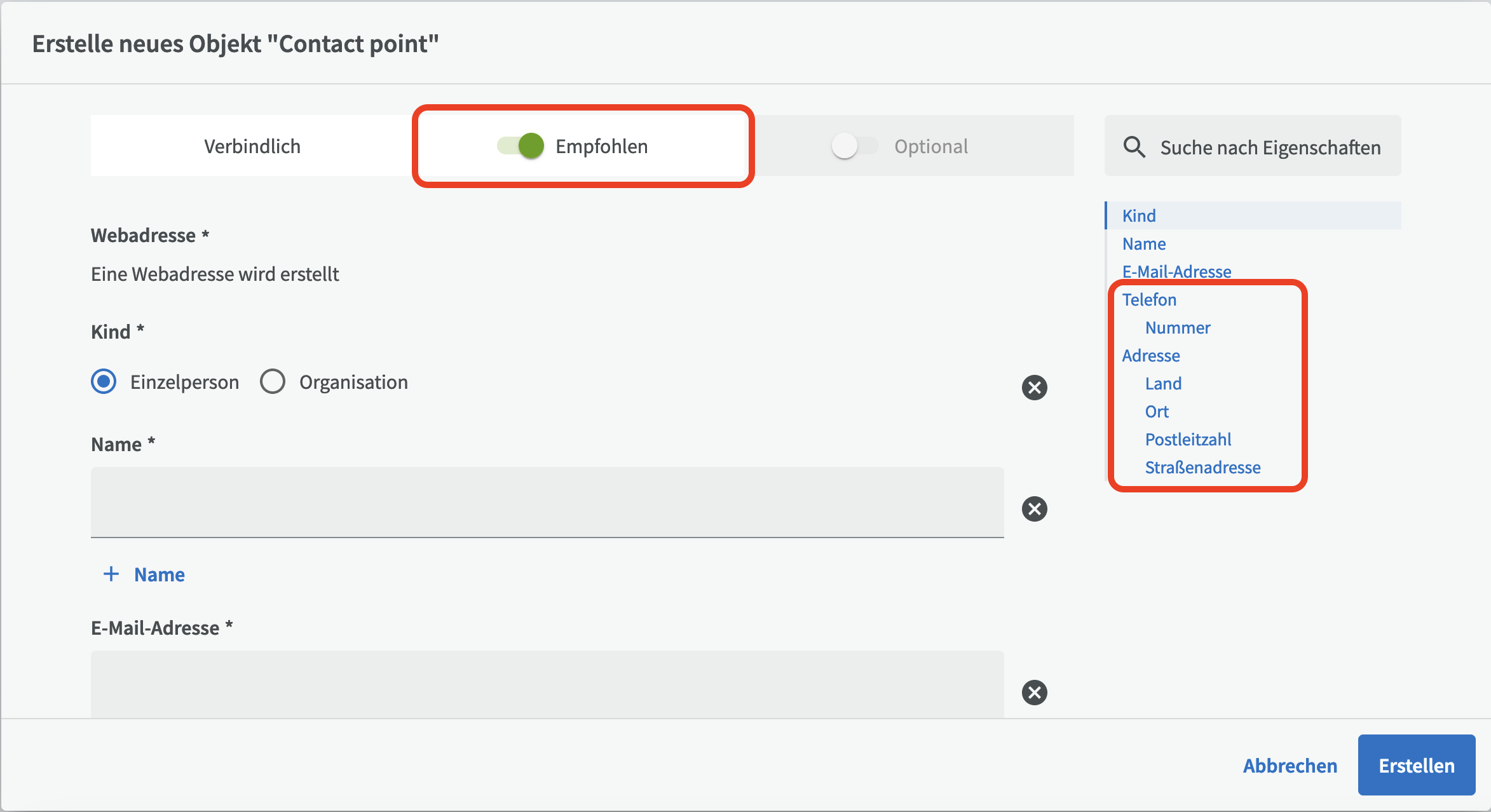
Wählen Sie zunächst aus, ob Sie eine Organisation (z.B. eine Abteilung/Einheit) oder eine Einzelperson als Kontaktpunkt eingeben möchten. Name und E-Mail-Adresse sind Pflichtfelder. Wenn Sie jedoch die empfohlenen Felder (oben) aktivieren können Sie weitere Informationen wie Telefonnummer und Adresse eingeben. Klicken Sie dann unten rechts auf die Schaltfläche Erstellen.
Beachten Sie, dass Sie hier keine vorhandenen Kontaktstellen bearbeiten oder entfernen können. Gehen Sie stattdessen im Hauptmenü zu Organisationen. Dort haben Sie vollen Zugriff auf alle Kontaktstellen.
Datensatz kopieren¶
Wenn Sie bereits einen beschriebenen Datensatz haben, den Sie kopieren möchten, gehen Sie zur Übersicht des Datensatzes und klicken Sie auf "Kopieren".
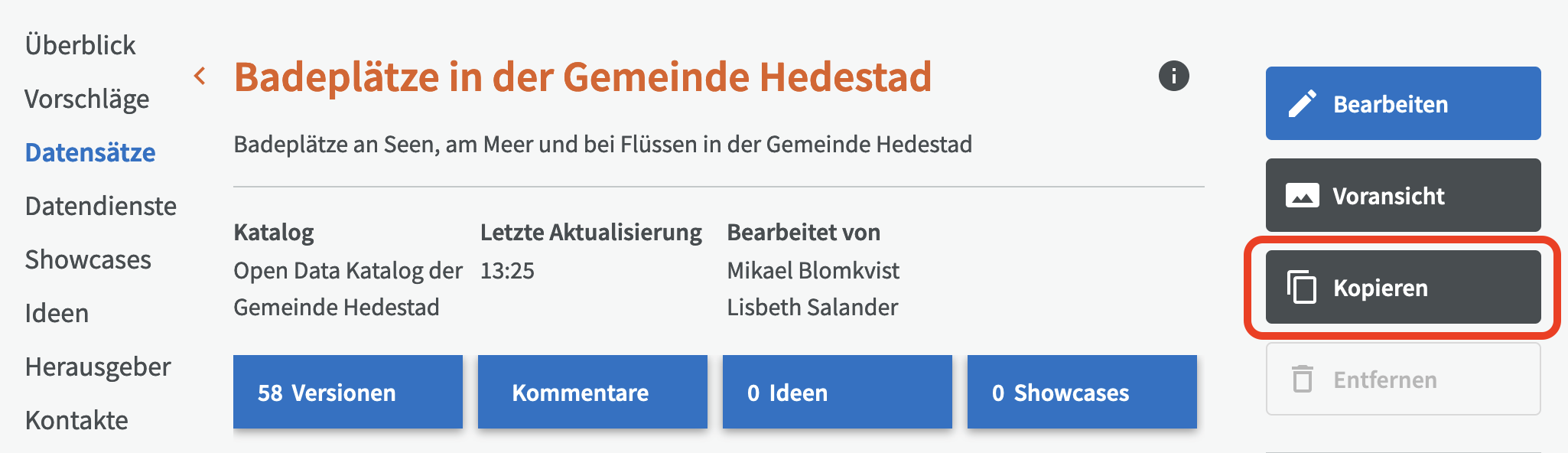
Anschließend können Sie wählen ob Sie eine oder mehrere Distributionen aus dem Datensatz kopieren möchten. Wählen Sie die Distributionen aus, die Sie kopieren möchten, und klicken Sie auf "Weiter". Bitte beachten Sie, dass Visualisierungen und Kommentare nicht kopiert werden.
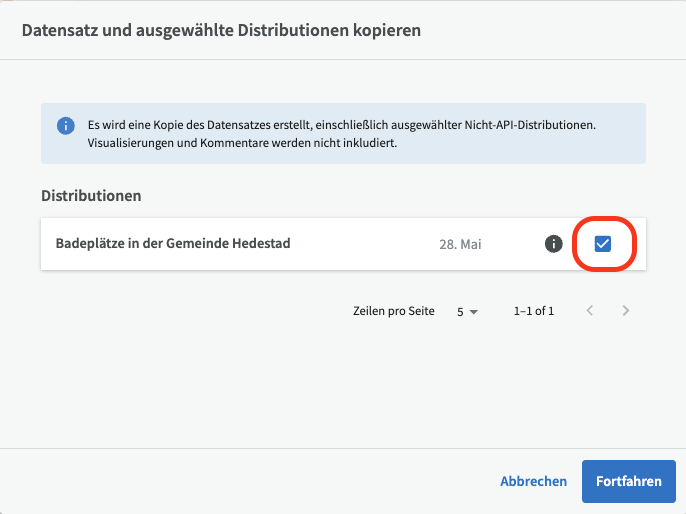
Tabellenansicht und Listenansicht¶
Standardmäßig werden die Daten in EntryScape Catalog in einer Listenansicht angezeigt. Wenn Sie viele Vorschläge oder Datensätze auf derselben Seite anzeigen und bearbeiten möchten, können Sie die Tabellenansicht verwenden. Wechseln Sie zur Tabellenansicht, indem Sie oben auf das Symbol für die Tabellenansicht klicken.
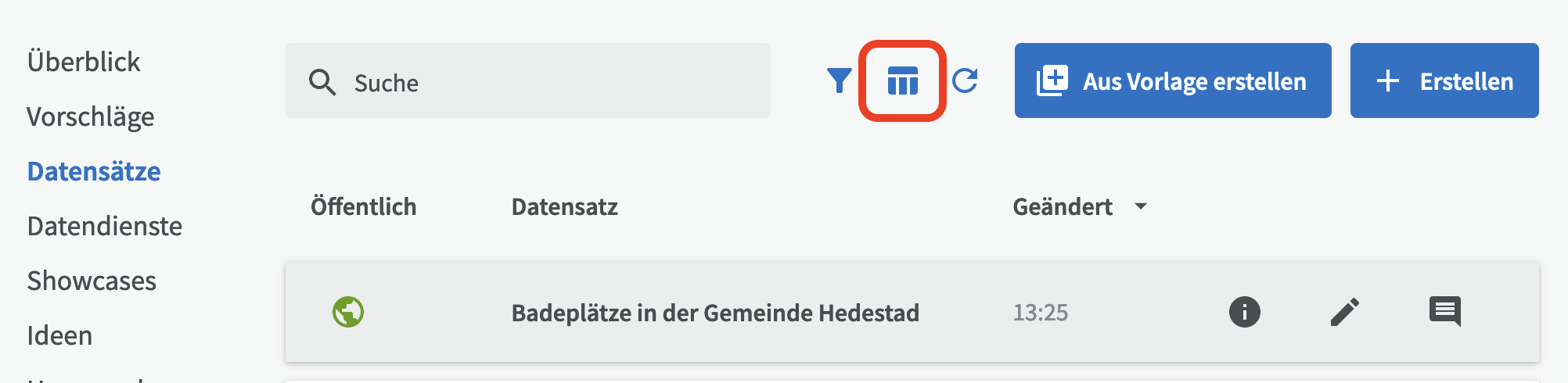
In der Tabellenansicht können Sie auch festlegen, wie viele Spalten gleichzeitig angezeigt werden sollen. Klicken Sie auf "Spalten", um festzulegen, welche Spalten angezeigt oder ausgeblendet werden sollen.
Bitte beachten Sie, dass je nach Komplexität des Feldes nicht alle Felder in der Tabellenansicht angezeigt werden können. Dies wird in einer zukünftigen Version von EntryScape verbessert werden.
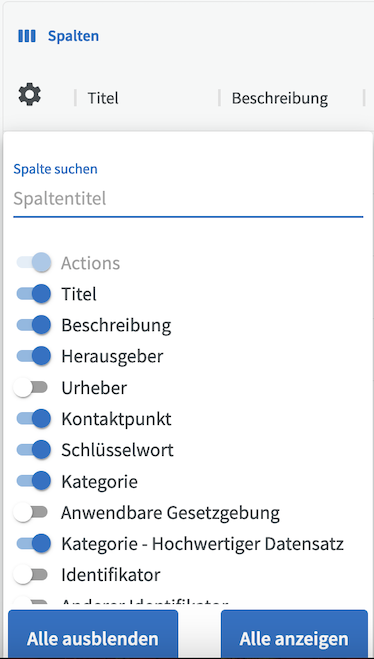
Klicken Sie auf das Feld, das Sie bearbeiten möchten, und geben Sie einen Wert aus der Dropdown-Liste oder einen Freitext ein. Um das Bearbeitungsfeld zu schließen, klicken Sie auf das obere X oder außerhalb des Felds. Vergessen Sie nicht, unten auf die Schaltfläche Speichern zu klicken, nachdem Sie fertig sind.
Um zur Listenansicht zurückzukehren, klicken Sie oben rechts auf das Symbol für die Listenansicht.
Detaillierte Informationen anzeigen¶
Wenn Sie detailliertere Informationen zu Ihrem Datensatz anzeigen möchten, klicken Sie auf das Informationssymbol.

Es wird ein Dialog angezeigt mit Metadaten, sowie Information zu allen Objekten die auf Ihren Datensatz verweisen oder von ihm ausgehen. Lesen Sie mehr über detaillierte Informationen.
Datensatz entfernen¶
Um einen Datensatz zu entfernen, gehen Sie zur Übersicht für den Datensatz und klicken Sie auf die Schaltfläche "Entfernen".
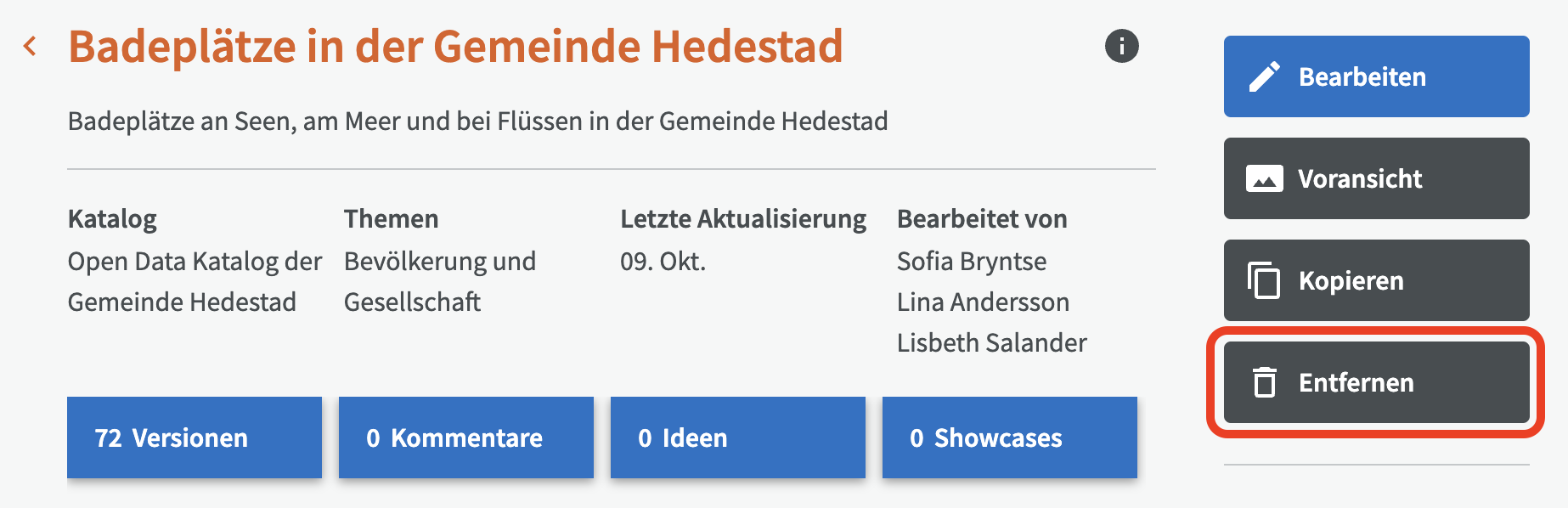
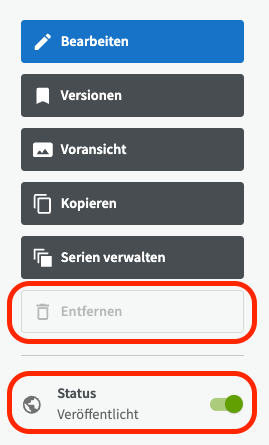
Beachten Sie, dass Sie nur Datensätze entfernen können, die nicht veröffentlicht sind. Wenn Sie also einen veröffentlichten Datensatz entfernen möchten, müssen zuerst durch Klicken auf die grüne Veröffentlichungsschaltfläche die Veröffentlichung rückgängig machen.
Datensatz veröffentlichen¶
Weitere Informationen zum Veröffentlichen von Katalogen und Datensätzen finden Sie auf der Seite Veröffentlichen.